Resumo
Um importante elemento da malha de controle é, sem dúvida alguma, o sensor. Ele é o responsável pela interface do sistema de controle com o processo real, permitindo que grandezas físicas sejam transformadas em informação e, desta forma, compreendidas e armazenadas. Há uma incrível diversidade de sensores em nosso universo, cada qual responsável pela leitura de uma grandeza específica (vazão, nível, temperatura, pH etc.) e seus valores são tão diversos quanto suas aplicações.
Além do elevado custo de alguns sensores, há ainda outros motivos que podem inviabilizar a leitura de determinadas grandezas. Algumas vezes não há sensor adequado para a variável que se deseja medir ou para as circunstâncias de leitura apresentadas.
Para casos como este, em que se faz inviável a leitura de uma grandeza física importante para o controle e/ou monitoramento de um processo, seja por não haver sensor específico disponível ou em que ele seja muito caro, lento ou inexato, mas em que se encontrem disponíveis digitalmente inúmeras medidas de diferentes sensores, torna se possível a criação de um sensor virtual (soft sensor) para se estimar a variável em questão, através do emprego de inteligência artificial. Isso também é chamado de gêmeo digital (digital twin) muitas vezes.
1. Introdução
Quando pensamos em aplicações de sensores virtuais em saneamento, um exemplo típico de processo aplicável é o de fermentação (Lotufo & Garcia, 2008), no qual o monitoramento da concentração de biomassa e/ou produtos secundários é essencial. No entanto, não há um sensor capaz de medir tais grandezas em tempo real, existindo basicamente duas formas de se obter informações ou medidas destas variáveis: por um método automático, através de um cromatógrafo ou análise de densidade óptica, com custo da ordem de U$ 8.000,00 (oito mil dólares); ou por método manual, através de amostras coletadas periodicamente e analisadas por um especialista, que não fornece sinais de forma contínua e nem sequer os fornece com frequência suficiente, o que não traz um resultado completamente satisfatório (Leal Ascencio & Herrera López, 2003 apud Lotufo & Garcia, 2008).
Segundo Lotufo & Garcia (2008), ” um sensor virtual consiste em um modelo que estima em tempo real a variável desejada a partir de dados medidos da planta. Na obtenção destes modelos são usados como dados de entrada os valores das variáveis que influenciam a variável desejada.
Também é possível definir que um sensor virtual “é a associação de um sensor (hardware), que permite medições on-line de algumas variáveis do processo, com um algoritmo de estimação (software) a fim de prover estimativas de variáveis não medidas, parâmetros do modelo ou superar atrasos de medições” (De Assis & Filho, 2000 apud Lotufo & Garcia, 2008).
O objetivo da criação de um sensor virtual é, muitas vezes, viabilizar o controle de determinado processo ou mesmo de possibilitar a sua otimização. Esta técnica permite o controle em tempo real do processo, baseado em dados estimados a partir de um modelo da planta.
Neste trabalho serão descritos os passos para a obtenção do modelo utilizado pelo sensor virtual e também a aplicação da técnica em um processo real na área de saneamento. O processo estudado corresponde a uma das etapas do processo de tratamento de efluentes.
Há inúmeros inconvenientes na utilização de sensores dentro do processo de saneamento, como atrasos de medida/ distância do ponto de medida, erros de leitura, ambiente hostil para medição, interferência no processo, custo/ dificuldade de compra em licitação, problemas de calibração etc.
Tendo em vista esta realidade, é muito frequente o monitoramento de variáveis importantes do processo através da coleta de amostras para a posterior análise em laboratório. Este tipo de monitoramento traz inevitavelmente a perda de densidade da informação, demora na obtenção dos resultados e normalmente o aumento do esforço humano, resultando no desvio do processo das condições de operação desejada, produzindo uma variabilidade insatisfatória e uma redução no rendimento do processo (Galindo Hernandez et al., 1998 apud Lotufo & Garcia, 2008).
2. Metodologia e análise dos resultados do sensor virtual
O sensor virtual e a criação do modelo
Como visto, um sensor virtual é projetado para substituir de maneira temporária ou permanente um sensor real de uma planta. A substituição temporária é motivada muitas vezes por falhas no sensor real, por compartilhamento com outras aplicações ou por ele ter sido retirado para manutenção. O sensor virtual também substitui com frequência análises laboratoriais realizadas a partir de amostras do processo, uma vez que significam quase sempre um atraso no controle do mesmo.
A Figura 1 mostra o diagrama de uma planta na qual a variável ‘Y, medida usando um sensor, pode ser substituída pelo sinal ‘ym’ fornecido pelo sensor virtual. Geralmente o sensor virtual é o modelo de apenas uma parte da planta e suas entradas são outras medições realizadas no processo (Lotufo & Garcia, 2008).
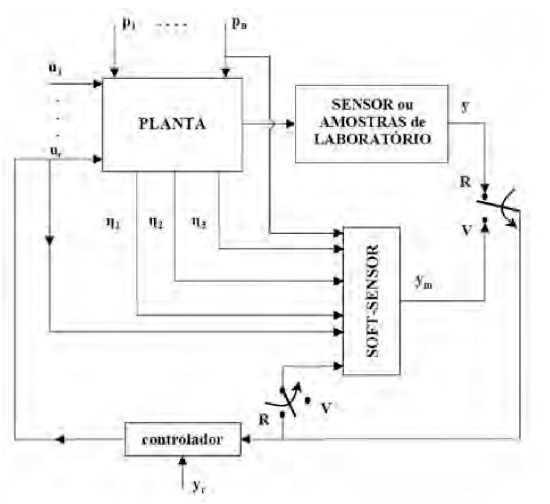
A criação do modelo da planta a ser utilizado pelo sensor virtual deve levar em consideração as variáveis que estão de alguma forma envolvidas com a variável que se deseja estimar. A quantidade de variáveis utilizadas para a geração do modelo irá impactar diretamente na complexidade do mesmo e, portanto, excessos devem ser evitados no intuito de tornar o modelo mais preciso e dinâmico.
A confiabilidade de um sensor virtual é outra questão muito importante a ser considerada. Ela deve ser verificada no momento em que o sensor virtual está para ser colocado em operação e também de maneira periódica, durante o tempo em que estiver em operação, uma vez que os processos são dinâmicos e estão sujeitos a constantes alterações.
Há diversos métodos utilizados para estimar variáveis através de outras variáveis medidas, que podem ser utilizados para a criação de um sensor virtual. Esses métodos podem ser classificados e divididos em três grandes grupos (Ljung, 1987 apud Lotufo & Garcia, 2008) e (Ohshima & Tanigaki, 2000 apud Lotufo & Garcia, 2008):
- Modelos Fenomenológicos — obtidos através de uma abordagem analítica, são os chamados modelos mecanicistas, derivados dos princípios básicos ou fundamentais;
- Modelos Empíricos — provenientes de dados obtidos em laboratório;
- Modelos Caixa-Preta — obtidos de dados operacionais através da aplicação de algoritmos como redes neurais, lógica nebulosa (fuzzy logic) e/ou métodos estatísticos, tais como análise multivariável e PLS (Partia/ Least Squares).
Segundo Lotufo & Garcia (2008), “um método que está se tornando muito popular e que vem sendo bastante utilizado é a rede neural artificial, que possui capacidade de aprendizado e adaptação pela imitação do funcionamento de sistemas neurais biológicos em um nível simplificado. Inspirada no funcionamento do cérebro humano, ela é baseada em simples elementos funcionais chamados neurônios, ligados entre si por conexões ponderadas por pesos que funcionam como parâmetros e que podem assumir diferentes valores. A escolha certa dos pesos permite identificar sistemas não lineares de maneira simples. ” Há ainda outras técnicas notáveis que podem ser utilizadas para a criação do modelo, como a lógica nebulosa, que consiste em uma generalização da lógica clássica para conceitos imprecisos, e o uso de algoritmos genéticos, que são baseados na teoria da seleção natural de Charles Darwin.
Exemplo de aplicação em saneamento
Há inúmeras aplicações na área de saneamento para as técnicas de modelagem já citadas. Em muitos casos é justificável o uso de sensores virtuais e/ou de outros recursos que possibilitem o controle avançado de processos.
Um bom exemplo de aplicação das técnicas de modelagem citadas é dado por Capanema (2008), num estudo desenvolvido na Estação de Tratamento de Água (ETA) do Rio das Velhas da COPASA — Companhia de Saneamento de Minas Gerais.
Nesse trabalho foi avaliada a utilização de instrumentação analítica para o controle do processo de coagulação da ETA e foram desenvolvidos modelos que, associados a técnicas de controle, pudessem ser utilizados para se efetuar o controle automático da dosagem de coagulante.
Segundo Capanema (2008), a coagulação é um dos processos fundamentais nos Sistemas de Tratamento de Águas Superficiais para fins de abastecimento público. Exceto nas unidades de filtração “lenta” a coagulação é responsável pela clarificação das águas, pela remoção da maioria dos metais pesados, além de agentes químicos e microbiológicos. Devido à relevância do processo, a aplicação dos produtos coagulantes na água a ser tratada (água bruta) requer critérios e cuidados que objetivem o seu melhor desempenho. Tanto a sub quanto sobre dosagem do coagulante podem comprometer a qualidade da água tratada, ocasionando a desconformidade com os requisitos preconizados pelo Padrão de Potabilidade Portaria: 51 8/2004 do Ministério da Saúde e/ou sobrecarregar as etapas subsequentes do sistema de tratamento, podendo levar a aumento dos custos operacionais, por exemplo, com o aumento do consumo de água tratada utilizada para lavagem dos filtros. Portanto, um bom controle do processo de coagulação pode reduzir custos operacionais, gastos com produtos químicos e garantir a conformidade com o Padrão de Potabilidade vigente.
O primeiro passo do trabalho foi definir as variáveis de estudo: vazão de água bruta, turbidez da água bruta, cor verdadeira da água bruta, condutividade da água bruta, pH da água coagulada e tipo de coagulante (densidade e concentração).
Em seguida foram desenvolvidos alguns modelos fazendo uso de diferentes topologias de Redes Neurais Artificiais (RNA) e Redes Neuro Fuzzy (RNF), com o intuito de se obter um modelo que representasse o comportamento do operador ao controlar a dosagem de coagulante e um modelo para efetuar a predição da turbidez da água decantada. Esses modelos foram criados em um programa desenvolvido na linguagem de programação C++.
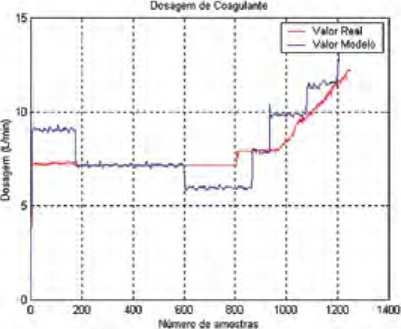
Finalmente, fazendo uso de recursos de automação disponíveis na ETA, conectou-se o programa a um sistema SCADA (Supervisory Control And Data Acquisition), tornando possível a aquisição dos valores das variáveis de entrada e o registro gráfico da saída de cada um dos modelos on-line. Os resultados são apresentados nas figuras 2 e 3.
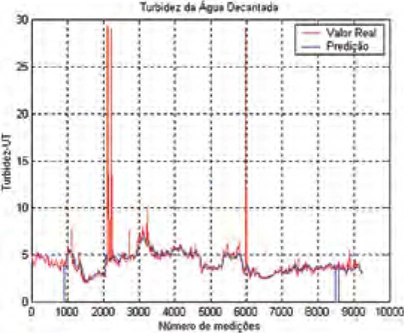
A Figura 3 apresenta os valores da turbidez real (vermelho) e de sua respectiva predição (azul) realizada uma hora e meia antes. E possível notar que os valores previstos são próximos dos reais. Na Figura 3 é apresentado o registro histórico diário para os valores de dosagem de coagulante que foram efetivamente praticados pelos operadores (vermelho) e aqueles que foram calculados pelo modelo resultante (azul). Mais uma vez é possível notar coerência entre os valores reais e os estimados.
Caso de estudo: processo de lodos ativados em ETE
O princípio de lodos ativados é um processo que lida com o tratamento de esgotos e efluentes industriais e faz parte do processo de uma Estação de Tratamento de Efluentes (ETE).
Pelo princípio de lodos ativados, uma vez que os efluentes receberam aeração e tratamento biológico suficientes, eles são descarregados em tanques de clarificação para posteriormente passar por tratamento químico adicional de purificação. Parte do material residual, o lodo ativado é devolvido para o sistema de aeração para ser realimentado ao tanque de entrada de novos efluentes. A Figura 4 ilustra parte do tratamento de esgotos e efluentes industriais, objeto de estudo deste trabalho, onde está inserido o princípio de lodos ativados.
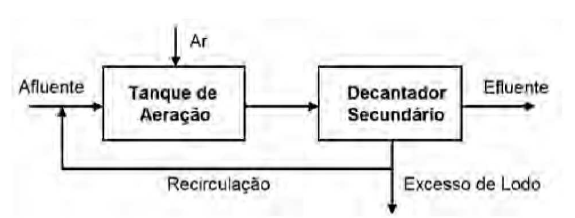
Para este estudo de caso, o indicador Settled Solids (sólidos em suspensão) indica quanto lodo ainda está suspenso nos efluentes ou na água limpa. E uma medida de laboratório, amostrada uma ou duas vezes por semana. Essa medida é importante para o controle da recirculação do lodo e da drenagem do lodo. Ela é utilizada em conjunto com outros indicadores orgânicos, tais como nitratos, amônia e oxigênio. O problema com o uso de Settled Solids como uma medição é que a amostragem é efetuada apenas algumas vezes por semana e, portanto, os resultados ainda precisam ser recebidos do laboratório após análise. Isso é muito tempo de espera para o controle de processo ideal. A forma mais eficaz e mais rápida de acompanhamento do processo é a implantação de um sensor virtual, que utiliza um modelo de processo usando outras variáveis conhecidas como entradas para o modelo. O sensor é então utilizado para o acompanhamento on-line do controle do processo, com feedback quase em tempo real para os operadores.
Passo a passo, a metodologia proposta para o desenvolvimento do sensor virtual da variável Settled Solids caminha sobre as seguintes fases:
- Escolha da ferramenta para modelagem;
- Classificação de variáveis e preparação dos dados históricos;
- Criação do modelo do processo;
- Aplicação do sensor virtual e análise dos resultados.
Escolha da ferramenta para a modelagem
Nas Referências 3 e 4 é possível ter acesso à descrição de exemplos de ferramentas de mercado que são disponibilizadas para a criação do modelo de processo e, consequentemente, do sensor virtual de qualquer planta de saneamento, ou mesmo de outros tipos de processo. Uma das possíveis aplicações é de um sistema de monitoramento de efluente preditivo, ou seja, um sensor virtual para aplicação em plantas de tratamento de águas com o intuito de predizer a demanda de materiais utilizados no processo. Esse tipo de sistema, em geral, visa à otimização de processos de controle, tendo por base valores históricos de operação e, em geral, contemplam algoritmos genéticos, PCA (Principal Component Analysis), análise de correlação, lógica Fuzzy e árvores de decisão.
Foi escolhida para a modelagem do processo e criação do sensor virtual uma ferramenta que diminui a complexidade do estudo (Ref. 3; Ref. 4) e possibilita a geração do modelo inferencial e a posterior aplicação do sensor virtual resultante em tempo real com a planta.
Classificação de variáveis e preparação dos dados históricos
Da mesma forma como descrevem Paiola & Vieira (2009), outro passo importante é a identificação da função de cada uma das variáveis dentro do sistema. Existem basicamente quatro funções: Meta (Target), Perturbação (Disturbance), Estado (State) e Controle (Adjustable). A meta é a variável que se deseja otimizar, isto é, manter em um determinado intervalo de valores ou que se deseja estimar através do sensor virtual. Neste estudo, a variável Meta é a Sett/ed Solids. As perturbações são os valores de entrada do sistema que podem ser medidos, mas não podem ser controlados. Os estados são medições produzidas pelo sistema, mas que não desejamos otimizar. Variáveis de controle são as que podemos manipular, mesmo que dentro de determinadas faixas de valores. Neste estudo foram levadas em consideração diversas variáveis reais, tais como medidas de amônia, oxigênio, vazão de saída de efluente, fluxo de sedimento secundário, fluxo de ar, etc.
A metodologia adotada é inteiramente baseada em medições históricas de processo, portanto é fundamental garantir a qualidade dos dados a serem trabalhados. Dois aspectos que devem ser observados são a taxa de amostragem e a amplitude de cada uma das variáveis. Neste passo, é importante utilizar ferramentas que facilitem a preparação dos dados (Figura 5).
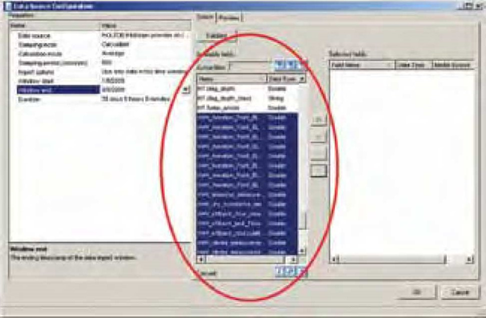
A taxa de amostragem deve ser suficiente para captar a dinâmica do processo. Um método teórico que pode ser usado como referência é o chamado teorema de Nyquist (Ogata, 2003). Ele sugere que a taxa de amostragem seja minimamente duas vezes menor que a menor constante de tempo do sistema.
Criação do modelo do processo e validação
O próximo passo é a geração de um modelo inferencial, que consiste em um modelo matemático criado a partir dos dados que foram preparados. A ferramenta escolhida baseia-se no princípio de redes neurais para a criação do modelo. Como já foi explicado, redes neurais são algoritmos matemáticos que imitam o funcionamento dos neurônios do cérebro animal para o desenvolvimento de programas que aprendem com base em uma série de exemplos. Sua principal vantagem sobre os métodos convencionais, como a regressão linear multivariável e a correlação cruzada, é que ela modela de forma bastante eficiente tanto processos lineares quanto não-lineares.
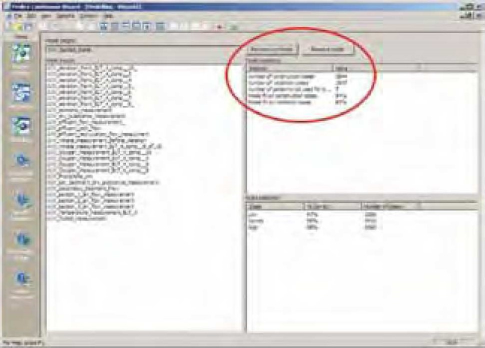
Um cuidado importante que deve ser tomado quando se lida com redes neurais é dividir os dados em conjunto de treinamento e conjunto de validação. Isso é necessário para testar se realmente o modelo descreve o funcionamento do processo ou simplesmente ‘decorou” a lista de dados passada para treinamento. Como pode ser visto na Figura 6, o ajuste da rede resultante foi muito bom, atingindo 93% entre os casos de validação. Na mesma figura, mais à esquerda, pode ser observada a lista de variáveis de entrada utilizadas para a geração do modelo.
Aplicação do sensor virtual e análise dos resultados
Com o modelo do processo criado e validado, as aplicações são diversas. Com ele, é possível simular situações de operação específicas e prever como seria a resposta do processo a um conjunto de condições. Além disso, é possível otimizar o controle do processo através da geração de regras e parâmetros de controle a partir do modelo, incluindo a possibilidade de aplicar-se o controle preditivo ao processo. No entanto, este estudo de caso limita-se à aplicação do sensor virtual à planta, através do uso do modelo criado.
O modelo gerado precisa ser alterado para a implantação em tempo real. O projeto, por exemplo, pode ser configurado para ler os dados a partir de uma fonte OPC que busca dados diretamente da planta, em tempo real. No caso da ferramenta utilizada, basta trocar a fonte de dados histórica por uma conexão OPC (Figura 7).
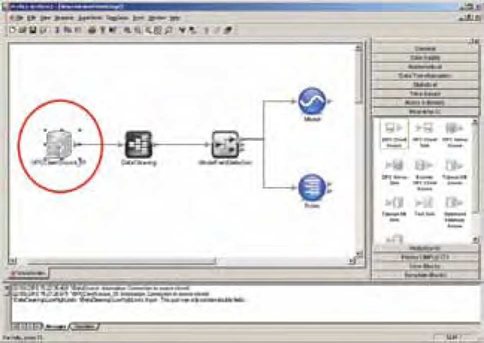
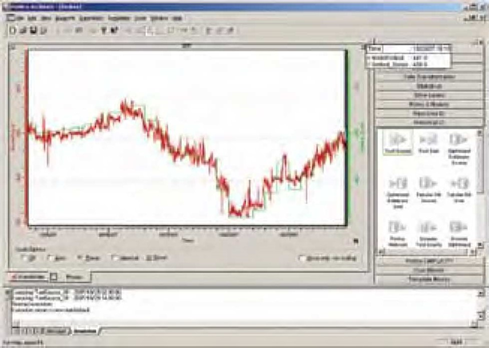
A partir deste ponto, o projeto resultante pode ser executado em tempo real, gerando valores estimados para a variável que podem ser automaticamente plotados em um gráfico de tendências. Na Figura 8 é apresentada a comparação entre os resultados do sensor virtual (vermelho) e os dados obtidos através de análise laboratorial (verde).
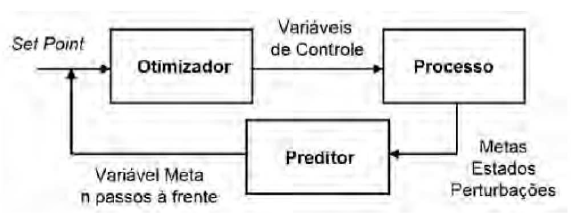
Com o sensor virtual obtido e validado, uma das possíveis aplicações é a implementação de um controlador preditivo, como mostrado na Figura 9. O controlador preditivo é aquele que, com base em um modelo do processo, simula seu comportamento alguns passos à frente e, por meio de um algoritmo de otimização, estima uma trajetória otimizada das variáveis de controle. Esse tipo de controlador é bastante eficiente em situações onde controladores PID não são eficientes, como em processos com grandes não-linearidades ou tempo morto.
3. Conclusão
Não há dúvidas de que os sensores virtuais significaram uma revolução na instrumentação moderna. Sua utilização viabilizou o uso de sensores em muitas situações em que os problemas apresentados pelo sensor real tornavam sua aplicação inviável.
A aplicação de sensores virtuais na área de saneamento pode simplificar ou reduzir os custos de controle de uma ETA ou ETE, uma vez que permitem a otimização e controle preditivo do processo ao qual estão aplicados. Muitas vezes o sensor virtual possibilita o monitoramento on-line de variáveis do processo que, até então, dependiam de análises laboratoriais para serem fornecidas. Isso possibilita o controle em malha fechada, diminuindo a dependência da operação manual e o tempo de resposta do elemento de controle.
Através dos resultados obtidos por Capanema (2008), pode-se observar que a aplicação no processo de coagulação em ETA trouxe resultados muito interessantes a despeito da complexidade do processo, que é multivariável, não-linear e composto por fenômenos físicos e químicos complexos. Pelos resultados apresentados nas Figuras 2 e 3, pode-se observar que o modelo resultante permitiu uma predição satisfatória dos valores reais.
No caso de estudo em ETE, com a implementação da metodologia proposta para a criação do sensor virtual foi possível encontrar um modelo geral de otimização para o processo que detalhou de maneira bastante precisa a dinâmica de interação entre as diversas variáveis utilizadas para o estudo. Analisando-se o gráfico de comparação entre os resultados do sensor virtual e os dados coletados por laboratório (Figura 8), pode-se notar a precisão do modelo. A estimativa em tempo real da variável Sett/ed Solids através do sensor virtual permitiu, neste caso, maior rapidez de resposta do sistema de controle, bem como a diminuição da variabilidade da medida controlada para o tratamento dos efluentes.
Referências bibliográficas
- CAPANEMA, Selma P. Instrumentação e Controle do Processo de Coagulação e Predição da Turbidez da Água Decantada. Anais do 12 0 Congresso Internacional e Exposição Sul-Americana de Automação, Sistemas e Instrumentação — ISA Show, novembro de 2008
- LOTUFO, Francisco GARCIA, Claudio. Sensores Virtuais ou Soft Sensors: Uma Introdução. Anais do 70 DINCON — Brazilian Conference on Dynamics, Controls and Applications, 2008.
- GE Vernova. Proficy CSense. Página visitada em 20 de maio de 2022. [https://www.ge.com/digital/applications/proficy-csense]
- Aquarius Software. Proficy CSense. Página visitada em 20 de maio de 2022. [https://www.aquarius.com.br/produto/proficy-csense/]
- PAIOLA, Carlos E. VIEIRA, Ricardo C. Métodos Computacionais para Otimização de Processos Metalúrgicos. Anais do XIII Seminário de Automação de Processos da ABM, outubro de 2009.
- OGATA, Katsuhiko. Engenharia de Controle Moderno – 4a Edição, 2003.